이전 뉴스레터11편에서 안면 인식시스템을 설명하면서 샴(siamese) 신경망 네트워크, 3중(Triplet) 손실 함수, 유사도 함수 등을 다룬 바 있다. 본 프로젝트에서는 Kaggle Flowers Recognition 데이터세트에 있는 600 개 꽃들의 라벨 없는 영상데이터들을 3중 손실함수를 이용하여 샴 네트워크상에서 훈련한다. 통상 딥러닝을 통한 영상 분류에 있어서 수백, 수천 이상의 훈련 샘플/이미지와 매우 큰 데이터세트가 필요하다는 인식과는 다르게 수백 건의 라벨 없는 이미지 데이터들로 3중 손실을 통한 훈련을 시행하여 임베딩끼리의 cosine 유사도로 이미지 유사도 검색이 가능한 지 살펴본다.
비지도 유사 이미지 검색 처리 절차

데이터 준비
본 프로젝트에 사용된 데이터세트는 이곳 에서 다운로드 받을 수 있다. 데이터세트 240 X 240 픽셀 크기의 데이지, 민들레, 장미, 해바라기, 튤립의 5가지 종류의 총 4242
개의 꽃 이미지를 보유한다. 본 시스템에서는 각 종류당 120
개만 사용하여 데이지 꽃부터 일련번호를 1번부터 부여하여 튤립까지 총 600번까지의 .jpg 파일을 anchor
디렉토리에 위치시키고 시작한다.
아래 섹션에서 설명하는 3중 손실함수로 훈련하기위해서 우선 anchor에 600개의 이미지들을 위치시키고, positive에 anchor 이미지와 쌍을 이루도록 증식 및 변환을
가하여 위치시키고 negative 이미지들은 임의로(random) 생성된
anchor 와 positive 이미지를 더해서 생성한다. 아래 그림 2는 anchor 이미지
들로부터 positive image 들을 생성하는 함수이다. ①은
이미지의 중앙 50%를 잘라내는 것이고 ②는 2번에 1번꼴로 이미지를 왼쪽에서 오른쪽으로 뒤집는다. ③은 임의 대비(contrast) 요소의 lower_bound=0.2, upper_bound를
1.8 로 설정. 이러한 이미지 증식방식은 이전 뉴스레터인 대조학습에서 효과적인 방법으로 언급된 방식을 차용하였다.

<그림 2. positive 이미지 생성 함수>
Data pipeline을 준비하기위해 아래 그림 3과
같이 anchor 와 positive 이미지들을 sort 된 순서로 불러와서 서로 match 되도록 한다.

<그림 3. Anchor, positive 준비>
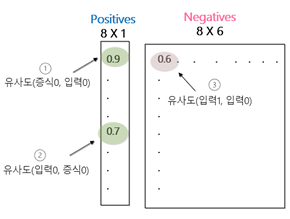
Negative 이미지들은 아래 그림
4와 같이 anchor 와 positive를 임의로 섞은 다음에 이 둘을 ③과 같이 concatenate 하여
생성한다. 이러한 이미지 들로부터 dataset을 생성한다.

<그림 4. Negative 이미지 생성>
anchor, positive, negative의 3가지 이미지가 같은 구조의 샴 네트워크에 입력되므로 이 세가지 dataset 을
zip 한 이후에 shuffle 하고 resize 한 dataset으로 변환한다. 그리고 아래 그림 5와 같이 train
과 valid dataset을 분할한다. ①은
train을 전체 80%로 할당하고 valid 는 그 나머지. ②는 batch
크기를 8로 설정했다.

<그림 5. Train, valid dataset 분할>
아래 그림 6과 같이 train_dataset을
출력해보니 첫번째가 anchor, 두번째가 positive, 세번째로
negative 이미지가 출력된다.

<그림 6. Triplet 데이터 확인>
아래 그림 7과 같이 ResNet50 모델
weight를 기반으로 customer layer로 3개의 dense layer를 추가하여 임베딩 layer 를 만든다. ①에 include_top=False로하고
우리가 원하는 customer layer를 추가한다. ②에
256 벡터크기의 dense2 layer가 output 이 된다. ③에 inputs은
base_cnn.input 이, outputs=output 으로
embedding을 생성한다. ④와 같이 함으로써, ResNet50 layer의 155번째인 conv5_block1_out부터 trainable=True로, 그 이전 층들은 False 로 선언한다. 전이학습을 통한 파인튜닝에 대한 내용은 이전 뉴스레터를 참고.

<그림 7. 임베딩 준비>
Siamese 네트워크 모델 준비
3중 손실의 훈련을 위한 모델을 수립하는 단계를 살펴보자.
샴(siamese) 네트워크에 관해서는, 이전
뉴스레터나 논문을 참고하기 바란다. 이를 위하여 anchor, positive, negative의 입력을 받는 3개
embedding 이 포함된 샴(Siamese) 네트워크를
아래 그림 8과 같이 구성한다. ①은 ResNet50 전이학습을 통한 encoder 파트. ②는 커스텀 layer로 추가한 파인튜닝 층. ③은 각각의 embedding layer. ④ap_distance는 anchor와
positive 사이의 거리를 나타내고, an_distance는 anchor와 negative 사이의 거리를 출력.
이러한 ap_distance 와 an_distance를
tuple 로 출력하는 DistanceLayer를 사용한다.

<그림 8. Siamese 네트워크>
DistanceLayer 클래스안에 아래 그림 9와
같은 ap_distance와 ap_distance 값을 tuple 로 return 하는 함수를 사용하여 모델에 [anchor_input, positive_input, negative_input]이 입력되고 output 은 ap_distance 와 an_distance 의 거리가 출력되도록 정의함으로써 Siamese_network
을 구성한다. 이 거리들이 이후 loss 산출에
사용된다.

<그림 9. 거리 측정 layer>
지금까지 비지도 유사 이미지 검색 절차 중 데이터준비, ResNet50 기반 임베딩 준비, Siamese 네트워크 모델 준비등에 대해서 살펴보았다. 다음 2편에서는 3중 손실을 통한 훈련 시행, 이미지 검색을 위한 특징 추출, 유사 이미지 검색 모듈에 대해서 살펴보겠다.