1편에 이어서 3중 손실을 통한 훈련 시행, 이미지 검색을 위한 특징 추출, 유사 이미지 검색 모듈에 대해서 살펴보겠다
3중 손실함수(triplet loss)
실제 프로젝트에서 딥러닝을 통한 이미지 분류를 처리하고자 할 때, 라벨이 부여된 수천 건의 데이터를 준비하는 문제 혹은 분류되는 이미지 종류(class)가 너무 많은 (안면인식과 같은) 경우에 봉착하는 경우가 많다. 2015년 구글에서 발표한 안면인식 FaceNet 논문 에서 컨볼루션 네트워크에서 안면 이미지와 유사 이미지, 그리고 다른 이미지의 3중 손실로 훈련하는 방법이 발표되면서 훈련에 zero shot learning 과 같은 비지도학습 가능성이 소개되었다.


<그림 1. Triplet loss 함수>
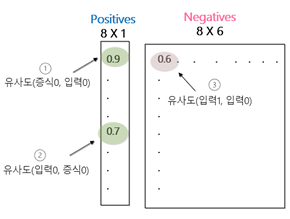
Loss는 아래 그림2의 ①과 같이 Siamese 네트워크의 출력인 ap_distance 와 an_distance 의 차이로 표시된다. ②와 같이 margin 을 두고 0.0 중에 최대치를 취하게 함으로써 음수 값을
갖지 않도록 한다.

<그림 2. 손실 산출>
3중 손실을 통한 훈련 시행
3중 손실을 통한 훈련 시행은 아래 그림 3과
같이 옵티마이저는 Adam을 채용하고 learning_rate는
0.0001, 그리고 epoch를 40으로 하였을 때, validated loss 가 ①과 같이0.0374로 나타났다.

<그림 3. 훈련 시행>
이미지 검색을 위한 특징 추출
컨볼루션 심층망을 통과하여
feature vector 가 생성된 layer를 임베딩(embedding)이라고 칭한다면 비교하고자 하는 모든 이미지들이 이러한 같은(동일한
파라미터 조건하의) 컨볼루션 망을 통과하면 결국 같은 길이의 임베딩으로 이루어질 것이다. 만약 이러한 임베딩들을 고차원의 벡터 공간에 위치시킨다면 같은 구조를 가진 임베딩끼리는 같은 위치에 모일 것이고
다른 구조를 가진 임베딩끼리는 멀리 떨어지게 된다. 우리는 자연어처리에서 word2vec 묘사들을 PCA를 통해 2차원에 투영했을 때 이러한 묘사를 볼 수 있다.
이전 1편 그림 7에서 정의한 embedding
layer를 참고로 다시 보자. 아래 그림 4의 ①과 같이 layer.trainable 상태를 출력해본다. ② 이전 그림에서 설정한데로
154번째 layer 부터 trainable 이 True 로 변경 되어있음을 확인할 수 있다.

<그림 4. layer.trainable 확인>
아래 그림 5와 같이 훈련된 siamese
모델로부터 특징 추출 모델을 생성한다. 3중 손실을 통한 훈련을 통해 생성된 Siamese 모델의 입력으로 embedding input이 output은 embeddig,out 즉 그림 4에서 살펴본 256차원의 output
이다.
Feature vector 추출

<그림 6. Feature vector 추출>
이 feature vector 추출
함수를 이용하여 비교할 대상인 전체 anchor 이미지들을 대상으로 한 데이터프레임 df 를 작성한다. 데이터프레임은 ‘file’과
‘features’를 컬럼으로 하며 각 row 당 df[‘features’]에 feature vector가 담기도록 만든다.
유사도 함수

<그림 7. 코사인 유사도>
함수로 정의된 코드는 아래 그림 8과 같다.
<그림 8. 유사도
함수>
유사 이미지 검색 모듈
유사 이미지 검색 모듈은 아래 그림 9에서 찾고자 하는 입력 이미지 파일인 file, 유사한 이미지를 전체
anchor 이미지들의 feature vector 가 담긴
데이터프레임 feature_df, 그리고 feature_model 과
model_name 을 매개 변수로 전달하여 ①에서 feature
vector를 img_features 로 추출하고, ②에서
getCosineSimilarity함수에 img_features와
비교할 numpy array 의 row[‘features’]를
행방향 원소들로 더해서(axis=1) featu_df[‘similarity’] 컬럼에 저장한다. ③에서 ‘similarity’ 컬럼을 내림차순으로 정렬. ④에서 유사도 순서로 5개의 파일을 출력하는 plotSimilarImages를 호출한다.

<그림 9. 유사
이미지 검색 및 출력>
이때 비교할 test
이미지도 순서대로 정렬하여 test_images_path 밑에 위치시킨 test_images 파일로 준비한다. 이러한 test_images로
anchor 이미지 중에 62.jpg 파일을 선택해서 test_images_path 밑에 위치시키고, 아래 그림 10과 같이 실행시키면 이미지 유사도 순서로 5개의 이미지가 출력된다.
아래 그림 10의
①에서 test_images에 여러 파일이 있다면 아래 그림과 같은 6개
이미지 블록이 그 수 만큼 표시된다. ②유사이미지 검색 모듈 호출, ③은
test_image 파일, ④는 기존 anchor 이미지들에도 62.jpg 가 있기 때문에 유사도 1.000 로 동일 파일이 나타난다.

<그림 10. 유사
이미지 출력>
결언