한글 경량화 Private LLM 개발
메타에서 2월에 Llama 거대 언어모델을 발표하였다. 커뮤니티의 연구자들은 그간 내부구조와 코드를 공개할 것으로 기대했던 OpenAI의 챗GPT의 다른 행보에 따라 거대언어모델에 관심이 높던 상태에서 Llama 언어모델 공개로 관심을 끌었다. 곧이어 스탠포드에서 이 언어모델에 instruction 세트들을 OpenAI 모델을 사용하여 instruction 과 ouput 형태의 데이터세트들로 파인튜닝한 instruction tuned LLM 을 선보임에 따라 연구 커뮤니티들은 후속되는 챗GPT를 모방할 수 있는 LLM 개발 가능성에 영감을 얻고 Llama 를 기반 모델로 한 후속 오픈소스 LLM 모델이 속속 발표되는 계기가 되었다.
본 프로젝트는 이러한 영문 오픈소스 LLM을 한글에 적용하는데 필요한 모델 개발을 목적으로 한다. 한글 챗GPT(GPT-3.5)와 같으면서 상용화가 가능하고 비교적 저 사양의 추론 환경에서 사용할 수 있도록 훈련 가능 모델 파라미터와 메모리 공간을 절약할 수 있는 QLoRA 와 4bit quantization 기술이 적용된 모델 개발을 목적으로 한다.
이러한 한글 경량화 LLM 은 OpenAI API 를 통한 외부 접촉을 통한 사용에 민감한 국내 기업들이 개별(Private) LLM 을 통하여 기업 내부 지식기반을 대상으로 한 챗GPT 운영의 필요성 대두에 기인한다. Alpaca 7B을 A100 8대로 8시간 훈련하여 OpenAI 의 챗GPT에 어느정도 근접한 성능을 보인다는 경로를 따라 영문 instruction 데이터세트 대신 한글 데이터세트를 이용한 파인튜닝을 시도해보고자 한다.
기반 모델
오픈소스 LLM 중에서 상용라이선스가 허용되며 한글데이터세트로 사전학습된 모델을 찾기가 용이하지 않았다. 아래 그림1의 허깅페이스 리더보드에 나타난 EleutherAI 사가 개발한 polygot-ko-12.8b 모델을 사용하였다. 이 모델은 Apache 2.0 라이선스에 한국 AI 스타트업 TUNiB 사에 엄선된 863GB 의 한글 언어 데이터로 사전학습된 모델이다. 영문 기반모델의 경우, 254대의 A100 GPU로 GPT-NeoX 모델을 1670억 토큰을 301,000 스텝 훈련하였다. 자세한 내용을 여기 참조.

<그림 1. Polyglot-ko-12.8b 모델 허깅페이스 리더보드>
한글 데이터세트
파인튜닝을 시행할 한글데이터세트는 허깅페이스의 beomi/KoAlpaca-v1.1a 데이터세트를 사용한다. 데이터세트는 v1.0 에서 Alpaca 의 5만2천개의 instruction 예들을 지도기반 파인튜닝한 영문 데이터세트를 DeepL 번역기로 한글로 번역한 데이터세트를 적용한 결과가 만족스럽지 않아 네이버 지식인에 있는 내용중 원문과 답변을 재가공하고 엄선하여 21,155 행의 instruction, output, url 형식으로 아래 그림 2와 같이 구성한 데이터세트다. url 은 네이버 지식인의 원문 출처다.

<그림 2. 한글 데이터세트>
KoAlpaca v1.1a 데이터세트 로드
아래 그림3과 같이, ① 허깅페이스의 datasets 를 설치, ② load_dataset을 도입, ③데이터세트를 로드한다.

<그림 3. 데이터세트 로드>
아래 그림4와 같이, lambda 함수를 사용하여 data를 변형시킨다. data 의 ‘text’ 컬럼을 ① 과 같이 ###질문: 에 이어, ② x[‘instruction] 이 뒤따르고, 답변도 같은 형식으로 이어진 다음 ③에 endoftext 코드로 마감한다. 즉 기존 ‘instruction’: ‘output’: 형식에 질문: 과 답변: 이라는 한글을 매핑한다.
<그림 4. 데이터세변형>
아래 그림5와 같이 GPU 사용을 위한 설정을 한다. 저자는A100 GPU 4개를 사용하지만 huggingface 가 bitsandbytes 의 4bit precision 으로 모델 weight 파라미터 크기를 줄이고 QLoRA로 LLM 파인튜닝에 메모리 사용량이 줄어들어 단일 24GB GPU 에서 33B LLM 을 파인튜닝할 수 있도록 하고 있어서 24GB 이상의 메모리가 가용한 GPU가 있는 환경에서는 이론적으로 파인튜닝이 가능하다. 자세한 내용은 여기 참조.

<그림 5. GPU 정의>
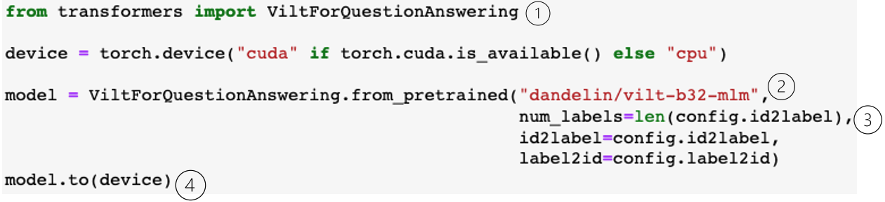
모델 로딩
아래 그림6의 ① safetensor 는 허깅페이스의 새로운 텐서 저장 형식으로 텐서를 간단하고 안전하게 그리고 pytorch 에 비해 2배 이상 빠르게 weight 를 로드할 수 있는 형식이다. Huggingface 에 있는 safetensor 모델을 model_id 로 정의한다. bitsandbytes의 4비트 quantization 을 사용하므로 ② 에서 load_in_4bits=True 는 .from_pretrained 방법으로 모델을 로드할 때 4비트 정밀도로 로드하고, bitsandbytes의 bnb_4bit_use_doule_quant=True로 중첩된 한번 더 양자화(quantization)를 사용함으로써 성능 감소 없이 보다 많은 메모리를 절약할 수 있다. ③에서 새로운 4bit 데이터형식의 weights 로 normal float 4(nf4) 데이터 형식을 사용한다. ④에서 은닉층의 행렬곱 등의 연산에 사용하는 연산 유형을 default 가 float32를 사용하는데 이를 bfloat16으로 변경함으로써 속도를 증가시킨다. ⑤에서 bnf_config로 정의하고, ⑥에서 추론시에 가능한 자원에 모델을 효과적으로 전개하도록 auto 로 정의한다.

<그림 6. 모델 로드>
text 부분 토큰화
아래 그림7의 ① 과 같이 data의 text 부분을 위에서 정의한 tokenizer로 토큰화 한다. ② 에서 dataset.map()과 같은 유틸리티를 batch와 함께 사용하면 프로세싱 속도를 높히고 생성되는 데이터세트의 크기를 자유롭게 통제할 수 있다. 단일 샘플보다 batch 모드를 이용하면 batch에 있는 모든 샘플의 토큰화를 병렬로 처리하여 속도가 빠르다.
<그림 7. text 부분 토큰화>
아래 그림8의 ① 과 같이 data train 컬럼에 첫번째 레코드의 text 컬럼내용을 조회하면 그림4에서 mapping 한 형태로 ### 질문: 이 나타나고 ② 의 ### 답변 그리고 ③의 endoftext 가 나타난다.

<그림 8. 토큰화된 text 내용 확인>
PEFT를 이용한 low bit 훈련 준비
아래 그림9의 ① 과 같이 정의하면 경사도 연산에서 그래프의 모든 단계의 내용이 마지막 경사도 변경 연산때까지 메모리에 저장되는 것을 필요할 때만 재연산하고 이전 값들은 날림으로써 메모리 사용을 절약한다. ②와 같이 준비함으로써 PEFT 를 사용하여 모델이 LoRa 즉 모델의 각 layer에 훈련 어댑터들을 추가하도록 준비한다.
PEFT는 거대언어모델을 효과적으로 파인튜닝하기위한 다양한 기술 방법들이고 LoRa 는 그 중에 하나다. LoRa 는 low rank adaption 으로 사전학습된 네트워크의 파라미터들을 파인튜닝동안 사용하지 않고(freezing) 별도의 소량 가중치(weights)를 부가하여 사용하는 방식이다. 이는 모델이 파인튜닝 기간에 원래 훈련되었던 것을 재앙에 가까울 정도로 잊어버리는 것을 방지하고 저장공간과 계산능력을 대폭 줄였다. 또한 파인튜닝에서 만들어지는 큰 크기의 체크오인트 파일과 달리 수 메가바이트의 작은 체크포인트 파일을 얻을 수 있기때문에 저장 공간 관리에 도움이 된다.

아래 그림10의 ① 부터 ②까지 LoraConfig 를 정의한다. r은 행렬 변경 순위다. 자세한 구성은 여기를 참고. ③에서 LoraConfig 로 모델을 호출 ④에서 모델의 훈련 파라미터를 출력하는 함수를 통해 훈련 파라미터가 ⑤와 같이 6.6GB 에서 6.55MB 크기로 0.099% 축소된 것을 확인할 수 있다.

<그림 10. LoRa 를 위한 준비>
파인튜닝 훈련
아래 그림11과 같이 huggingface 의 Trainer 와 DataCollatorForLanguageModeling을 사용하여 훈련한다. ① 에서 우리는 GPT NeoX 토크나이저(Polyglot 모델이 GPT NeoX 기반)를 사용하고, GPT NeoX 가 EOS 토큰 ID 를 가져야 하므로 PAD에 디폴트 값인 EOS를 부여, ②와 같이 허깅페이스의 transformers 에 최적화된 Trainer class 를 사용한다. ③과 같이 훈련 중의 구성을 TrainingArguments에 명시할 수 있다. 순서대로 훈련 중 기기당 배치 크기, 역전파 시행 전 경사도 수집을 위한 변경 단계 수, 전체 훈련 스텝 수, 학습률, 16비트 정밀도 사용, 100번 마다 로깅, 훈련 결과 디렉토리, 옵티마이저 사용. ④에서 DataCollator 는 데이터가 같은 길이가 아닐 경우 자동으로 최대 길이로 패딩된다. 마스크언어모델은 사용하지 않기때문에 False 로 세팅. ⑤와 같이하여 warning 메세지를 방지한다. 이후 추론할 때는 다시 True 로 설정 필요. ⑥에서 파인튜닝 훈련이 시작된다.

<그림 11. Trainer 를 통한 훈련>
아래 그림 12와 같이 ① 을 통해 추론 모드로 전환, ②에서 추론을 위해 다시 True로 전환.
<그림 12. 추론모드로 전환>
프롬프트 양식 작성
아래 그림 13과 같이 instruction 과 response 포함한 프롬프트 양식을 작성한다. Alpaca에서 사용되던 프롬프트에 한글을 추가하여 구성하였다. ① 과 ②는 instruction 과 response 사이에 참조할 input 이 있느냐 의 여부로 구별됨. ③은 Alpaca 데이터셋의 영문 instruction 밑에 한글로 번역본을 첨부한 형식. ④는 Instruction, Input, Response 로 출력되는 양식. ⑤에서 작성한 prompt_template 를 custom.json 파일형태로 저장한다.

질의에 대한 응답 함수 작성
아래 그림 14와 같이 질문을 입력하면 출력이 되는 함수를 작성한다. ① 과 같이, model.generate 를 통해 생성되는 결과를 응답으로 사용, ② 여기에 입력되는 질문은 tokenizer를 통과하며 ③과 같이, ### 질문: “실제 질문” 라인 바꿔서 “### 답변:” 형식으로 변환되는 return_tensors 는 파이토치 텐서(‘pt’)로 인코딩 된다. ④ 최대 토큰 수는 256 등의 매개변수 선언, ⑤에서 최대 토큰으로 생성된 첫번째 출력을 토크나이저로 decode 하여 출력한다. 훈련이 충분치 않을 경우에 <|endoftext|> 토큰을 잃어버릴 수 있다. 256 최대 토큰을 사용할 경우, 통상 3분 이상의 생성 시간이 소요된다.

<그림 14. 질의 응답 함수 작성>
응답 함수 출력
아래 그림 15와 같이 응답 함수를 출력한다. ① 출력 소요 시간 측정을 위해 time 설정, ② gen 함수에 질문을 입력하면, ③과 같이 답변이 출력되고 소요시간이 70초(약 1분 10초) 소요된 것으로 나타난다.

<그림 15. 응답 함수 출력>
결언
지금까지 polygot-ko-12.8b 오픈소스 LLM 에 한글 데이터셋으로 메모리 사용량과 훈련 파라미터 크기를 줄이는 4bit quantization 과 QLoRa 기술을 활용하여 한글 질의에 대해 응답하는 오픈소스 경량화 한글 LLM으로 파인튜닝을 하여 모델을 생성하는 과정을 살펴보았다.