지난 1편에 이어 2편에서는VQA 데이터셋 생성, 모델 정의, 훈련 및 저장, 그리고 저장된 모델로부터의 응답 추론에 대해 살펴보겠다.
VQA 데이터셋 생성
1편의 그림 3의 영상-언어 트랜스포머 구조에서 보았듯이 트랜스포머 인코더에 단어 임베딩과 이미지 조각이 펼쳐진 임베딩이 입력된다. Pytorch dataset 을 생성하여 영상, 질문(언어), 응답이 포함된 데이터셋을 생성한다. Pytorch Custom 데이터셋과 데이터로더를 작성하는 방법은 여기를 참조. 이 튜토리얼의 __getitem__ 부분을 아래 그림13과 같이 작성한다.
Huggingface 의 ViltProcessor 는 모델의 이미지를 준비하기위한 ViltFeatureExtractor 와 텍스트를 위한 BertToeknizerFast 를 변수로 받아 단일 processor 로 제공한다. ViLT에서 사용될 이미지와 텍스트를 연합한 인코딩 형태의 입력을 만들어준다.
ViltFeatureExtractor 는 이미지의 크기 변환, 정규화등을 통해 pixel_values 와 pixel_mask 를 생성한다. BertTokenizerFast 는 텍스트를 tokenize 하고 input_ids, attention_mask, token_type_ids 를 생성한다. Tokenizer는 입력 문장을 단어 혹은 서브 단어 단위로 쪼갠 후 사전에 등록된 id로 변환해주는 과정이다.
Bert Tokenizer 에 대해서는 이전 뉴스레터 16호의 Tokenizer 부분을 참고.
아래 그림13의 ①은 id_to_filename 을 통해 image 가 위치한 전체 이미지 경로 파일 이름을 획득하여 image 를 호출. ②에서 ViltProcessor에 이미지와 텍스트가 입력된다.

<그림 13. Pytorch 커스텀 데이터셋으로 작성한 VQAv2 데이터셋 정의 일부>
입력의 최대 길이로 남는 부분은 채워지고(padding), 넘는 부분은 잘라버리고 (truncation), Return tensor 는 Pytorch tensor 로 리턴 한다. ③으로 라벨 크기만큼의 1차원 targets tensor를 만든다. 사용되는 라벨 수는 3129 개다. ④로 3129 라벨에 해당되는 인덱스 위치에 해당 scores 가 기록된다. ⑤라벨 길이만큼의 텐서 targets 이 ‘labels’로 인코딩 된다. ⑥데이터셋이 인코딩을 리턴 한다.
아래 그림 14는 VQA데이터셋 생성 정의이다. ①에서 붉은색의 masked language modeling 사전학습으로부터 processor 를 호출한다. ②앞의 VQA데이터셋 생성의 입력 변수로 questions 의 길이 100까지, annotations 의 길이 100까지로 하여 processor 와 함께 호출한다.

<그림 14. VQA 커스템 데이터셋 생성>
아래 그림 15의 ①에서 첫번째 dataset 의 key 값들이 보여진다. ②에서 processor로 input_ids 인코딩 값을 디코딩한 출력이다. 질문 앞에 [CLS], 문장 끝에 분리 [SEP] 그리고 나머지에 패딩[PAD]가 채워져 있다. ③에 labels 에 있는 인덱스 id 형태 라벨들을 config 에 있는 id2label 을 통해 라벨 값으로 치환한 값들을 출력하고 있다.

<그림 15. dataset 의 input_ids 와 labels>
영상 및 언어 트랜스포머 질의응답 모델 정의
아래 그림 16은 모델 정의 부분이다. ①에서 huggingface 의 transformers로부터 질의응답 모델을 위해 ViltForQuestionAnswering 를 import 한다. ②에서 dandelion/vilt-b32-mlm 즉, vilt 32 patch 크기의 마스크 언어모델 weight 를 사용한 ViltForQuestionAnswering 모델을 정의한다. 이때, ③라벨 수는 config.id2label 의 길이로 그리고 id2label 과 label2id 를 config 정의를 이용하여 초기화해준다. ④에서 GPU를 사용할 경우 GPU device로 이동하도록 설정한다. 이로써, 모델은 임베딩 층을 거쳐 12개의 multi-head self-attention 층 그리고 마지막으로 linear classifier 가 포함된 모델로 정의된다.
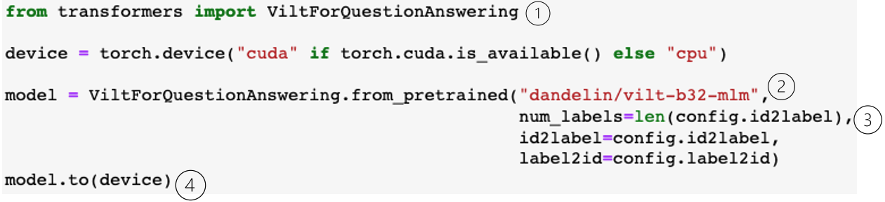
<그림 16. 질의응답 모델 정의>
Pytorch DataLoader 정의
다음으로 데이터셋을 배치로 데이터로드로 호출하는 과정에서 아래 그림 17의 ①과 같이 배치데이터로부터 가장 큰 이미지에 맞추어 패딩과 마스크를 생성 변환하여 배치를 리턴하는 함수 collate_fn 을 정의한다. 이는 모델에 입력되는 이미지의 최대 크기에 맞춰 나머지 차이나는 부분들을 패딩으로 채우고 패딩부분은 마스크가 0으로 표시된다. ②와 같이 배치의 인코딩 item을 ③에서

<그림 17. 배치 데이터 이미지 픽셀, 마스크 생성 변환 함수>
processor 의 ViltFeatureExtractor class에 있는 pad_and_create_pixel_mask 함수를 이용하여 batch의 픽셀값을 패딩하고 상응하는 픽셀 마스크를 생성한다. 이때 형태는 (batch_size, height, width) 로 어떤 픽셀이 실제(1)이고 어떤 픽셀이 패딩인지(0) 표시된다. ④에서 변환된 픽셀값과 픽셀마스크 값은 batch dictionary에 순서대로 torch.stack을 통해 쌓이게 된다. ⑤ 에서 dataloader 매개변수로 collate_fn 을 호출하여 pixel_value, pixel_mask 를 변환한 값이 batch에 반영되게 한다.
아래 그림 18의 ①을 통해 첫번째 interation 으로 데이터로더로부터 데이터를 가져오고, ②에서 픽셀 값이 [3, 384, 544] 로 (앞에 3은 채널) ③에서 픽셀마스크가 [384, 544] 형태로 확인된다. 앞의 4는 batch 크기다. ④에서 라벨 값 3129가 확인된다.

<그림 18. 배치 내의 item 확인>
모델 훈련
아래 그림19 의 ①에서 optimizer로 AdamW, learning rate 는 5e-5 로 설정. epoch를 50으로하고 ②에서 Pytorch training 을 시행한다.


<그림 19. 모델 훈련>
③은 50 epoch 훈련 후의 loss 를 나타낸다. 지금까지 ViLT 사전훈련 모델을 이용하여 질의응답에 파인튜닝하는 절차에 대해 살펴보았다.
추론을 위한 image, question 준비
자 이제부터는 추론을 위하여 먼저 추론할 image, question을 준비하는 것으로부터 시작해보자. 아래 그림 20의 ①과 같이 COCO 이미지 데이터세트에서 이미지를 하나 선택하고 ②에서 url 로부터 image 를 담게되고, ③에서 연관되는 질문을 생성한다.

<그림 20. Image, question 준비>
image 는 아래 그림 21과 같이 출력된다.

ViLTProcessor 를 이용하여 image 와 text 쌍을 준비
우선 준비된 image 와 text 를 ViLTProcessor을 이용하여 아래 그림 22와 같이 huggingface 의 VQAV2 에 파인튜닝된 ViLT 모델의 image 와 text 쌍을 준비한다. ①과 같이 hugginceface transformers 로 부터 ViLTProcessor 를 import 하고 ②에서 VQAV2에 파인튜닝된 모델로부터 ViLTProcessor 를 로드하여 processor 로 지정한다. 앞에서 살펴본 바와 같이, BertTokenizerFast 토크나이저가 사용되며 input_ids, attention_mask, token_type_ids 를 생성한다. ViltFeatureExtractor 가 이미지 크기 재조정 및 정규화를 담당하며 pixel_values 와 pixel_mask 를 생성한다. 이때 pixel_mask 는 batch 에서만 관련이 있는데, 어떤 픽셀이 실제 픽셀인지 패딩인지 여부에따라 1과 0으로 표시된다. 추론에서는 하나의 예(example)만 다루기때문에 모든 pixel_mask 는 이 경우 1 이다.
모델에 입력될 인코딩 준비
추론을 위하여 준비된 image 와 text쌍을 모델에 입력하기위한 인코딩 작업을 담당할 processor 를 사용하여 아래 그림 23과 같이 encoding 하고 차원을 확인한다. ①과 같이 processor 에 image, text 를 넣어주고 파이썬 텐서를 생성한다. ②에서 인코딩 아이템들의 형태를 표시해본다. ③에서 pixel_values 가 정확히 표시됨을 확인한다. 맨 앞의 batch 값은 추론을 위한 한개의 예만 입력되므로 1 이다.

ViLT VQAV2 데이터셋에 파인튜닝된 모델 로드
추론을 위하여 huggingface hub 으로 부터 vilt 모델이 vqav2 에 파인튜닝된 모델을 아래 그림 24와 같이 로드한다. ①과 같이 vqav2 에 파인튜닝된 사전훈련 모델을 사용하여 huggingface 의 ViLTForQuestionAnswering 모델을 로드한다.
forward pass 를 통한 답변 예측
그 다음 추론을 위해 아래 그림 25와 같이 모델을 통해 forward pass 를 진행한다. ①과 같이 input_ids, pixel_values 등이 포함된 인코딩을 model 에 forward pass한다. 이때 outputs.logits 의 차원은 (batch_size, num_labels) 의 형태를 띄며 이 경우, (1, 3129)가 된다. VQAV2 의 답변(라벨)은 3129의 가능한 답변이 있다. torch.sigmoid 를 통해 3129개의 라벨에 대해 0 에서 1 사이의 값을 보유하게 되고 최대값이 있는 id 가 idx 로 출력된다. ③에서 idx 에 해당하는 id2label 을 통해 label 값이 출력된다. ④에서 “How many cats are there?” 에 대한 답변이 2 로 출력된다.

1편에 이어 2편에서 VQA 데이터셋 생성, 질의응답 모델 정의, 모델 훈련, 추론을 위한 image, text 쌍 준비, 인코딩 준비, 파인튜닝된 모델 로드 그리고 답변 예측에 대해서 살펴보았다.









