1편에 이어서 2편에서는 Linear layer, Query, Key, Value 개념 그리고 multi-head self-attention 동작에 대해 살펴보고자 한다.
Linear Layer
아래 그림 10의 ① 의 단일 위치를 인식하는 word embedding 이 Linear 층에 입력되기위해서는 transpose(전치행렬)하여 ② 와 같은 형식으로 입력된다. 5차원의 벡터 입력이 ③의 3개 노드와 연결된 완전연결층을 통과한다. 5개의 임베딩 벡터 입력을 3개 노드로 통과시켜 ④의 3개의 임베딩 벡터로 축소시켜 연산 비용을 절감하는 효과를 갖는다. ③의 3개 노드는 5개 입력 벡터와 각각의 weight 값들을 사용하여 연결 되어있다. 이 weight 들은 scaler 숫자들로 ⑤는 이 값들을 행렬로 표시한 것이다. 이 값들은 모델이 back propagation 을 통하여 최적화하면서 결정된다. 이 weight 값들은 모델에 ⑤와 같은 행렬로 주입된다.

<그림 10. Linear Layer>
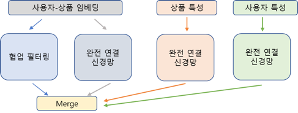
지금까지 Linear 층이 하는 일을 살펴보았다. 그런데 이전 1편의 그림 9의 ①을 보면 Linear layer 가 3개가 있다. 왜 일까? 각 Linear 층은 특별한 기능을 담당한다. 이 3개의 Linear 를 각각 Query, Key, Value Linear 층이라고 부른다.
Query, Key, Value
query, key, value 이 3가지 기능들은 전통적 자연어처리의 순차적 네트워크와 다르게transformers 가 attention 만을 가지고 자연어처리를 어떻게 하는가를 이해하는, 즉 self-attention 에 대한 중요한 부분이어서 비유적으로 좀 더 자세히 살펴보도록 하겠다.
먼저 아래 그림 11과 같이 유튜브를 통해 기아 신차 ‘EV7’ 을 검색한다고 가정해보자. 검색창에 EV7 이라고 입력하는 것이 ①Query(Q) 라고 한다면, 이 질의에 해당하는 리스트로 나타난 붉은색 사각형이 Key인데 이 중 첫번째가 가장 유사한 것이니까 ②Key(K1), 이 Key1 에 해당하는 value 즉 동영상 콘텐츠는 ③Value(V1) 이라고 할 수 있다.

<그림 11. Query, Key, Value>
코사인 유사도(Cosine Similarity)
위의 Query, 와 Key 는 질의 문장(‘EV7’)의 임베딩 벡터와 유사한 벡터를 유튜브 내부문장에서 검색하는데 이때 벡터 간의 유사도를 측정하는 것이 코사인 유사도이다. 아래 그림 12의 ①이 코사인 유사도 식이다. 코사인법칙은 고등학교 2학년 수학시간에 배운다. 이를 파이선 함수로 표현한 부분이 ④로 분자는 A, B 간의 벡터 곱이고 ⑤의 분모는 np.linalg.norm 즉 행렬 norm 들의 곱이다. 이것을 위의 그림 11의 Q(질의) 와 K(키) 간의 유사도 측정이라고 생각해본다면, 분자는 ②와 같이 Q 와 K 의 행렬 곱이 되고, 분모는 ③과 같이 크기의 정도로 대치될 수 있다. 이 식이 이후 설명할 3개의 Linear 와 self-attention 관계에 사용되니 잘 기억해두자.

<그림 12. 코사인 유사도>
self-attention
자 그럼 위에 살펴본 코사인 유사도는 attention 과 어떠한 연관이 있을까? 아래 그림 을 보면 Query, Key, Value 가 모두 다른 내용인데 왜 같은 Linear 층을 3개나 가지고 있을까?
아래 그림 13의 ①에 when you play the game of throne 이라는 문장이 positional embedding 벡터의 형태로 ②의 3개의 Linear 층에 각각 입력된다.

<그림 13. Linear 층>
이때 그림 14와 같이 transpose(행렬전치)된 ①의 위치 임베딩 벡터가 앞의 그림 10의

< 그림 14. Query, Key, Value 행렬 생성>
Linear 층의 ② 5 X 3 행렬과 행렬 곱의 연산이 일어나고 그 결과 ③과 같이 각각 7 X 3의 Query, Key, Value 행렬이 만들어진다.
Query 와 Key Linear 행렬의 MatMul
이제 아래 그림 15의 ①의 Multi-head self-attention 층 내부의 MatMul(Matrix Multiplication)층을 통과하는 단계로 왔다. 이전 그림 11의 유튜브 비디오 검색 예에서 Query 와 Key 가 ‘EV7’ 과 유사한 비디오 컨텐츠를 검색하는 것에 착안하면서, 우선 Query 와 Key 에만 집중해보자.
Query 와 Key 행렬이 행렬 곱(MatMul)이 실행되기위해 ②의 7 X 3 Query 행렬이 ③의 Key 행렬의 Transpose 와 행렬 곱을 수행한다. 그 결과, ④의 7 X 7 크기의 Attention Filter 를 얻는다. 즉 아래 그림 왼쪽의 ①번 즉, Query 와 Key 의 MatMul  이 수행된 것이다.
이 수행된 것이다.

<그림 15. Attention Filter 생성>
Scaled Attention Filter
위 그림 15 ①의 MatMul 수행 결과로 탄생한 Attention Filter 는 아주 중요한 출력으로 좀 더 자세히 살펴보자. 아래 그림 16의 ①은 Q와 K 행렬 곱의 출력 attention filter 다. 이 7 X 7 행렬의 값들은 초기에는 임의의 수로 채워지지만, 이전 그림 10의 ⑤와 같은 Linear 층의 weight 값들이 훈련을 통해 변경되어 문맥을 이해하는데 최적화되도록 훈련이 끝나고 나면 아래 그림 16과 같이 단어 간의 attention score 를 표시하게 된다. ②에서 가장 attention 점수가 높을 관계는 당연하게도 자기 자신들끼리 의 관계로 game 열과 game 행이 98로 가장 높다. 다음으론 ③의 play 열과 game 행인 90 이다. game 열과 play 행도 마찬가지로 90 으로 이 두 단어의 유사도는 가장 높다고 할 수 있다. 이렇게 단어들 간의 유사도를 유추하는 Filter 다.
이제 ④의 Scale 층의 연산을 통과하게 된다.

<그림 16. Scale 로 나눈 Attention Filter>
Q 와 K 간 유사도를 측정하는 것은, 결국 아래 그림 17과 같은 연산을 수행한 것이다. ③의 scaling 을 Key 행렬 차원의 크기의 제곱근 즉 우리의 경우는 attention filter 가 7 X 7 행렬 차원이므로, 으로 나눈 값이 된다.

< 그림 17. Q 와 K 간 유사도 함수>
논문에서는 아래 그림 18의 ①과 같은 layer 들의 구조를 Scaled Dot-Product Attention 이라는 이름으로 설명하고 있다. 즉, 이 부분을 식으로 표현한다면 ②와 같은 Q, K, V 행렬을 통한 attention 함수로써, 빨간색 박스 안의 수식으로 표시할 수 있다. 이 중에 ③의 파란색 네모안에 부분이 지금 Scale layer 를 통과한 시점까지의 연산을 표시한다. 코사인 유사도함수의 분모인 scaling 부분을  로 나누고 있는데 이 부분을 논문은 이렇게 설명하고 있다. 만약 dk 즉 Key 의 차원이 커지면 분자 즉, Q * K T 의 크기가 커지고, 여기에 softmax 함수가 적용되면 각 차원의 값이 매우 작은 경사도(gradient) 영역으로 이루어진 값을 갖게 한다. 이를 방지하기위해
로 나누고 있는데 이 부분을 논문은 이렇게 설명하고 있다. 만약 dk 즉 Key 의 차원이 커지면 분자 즉, Q * K T 의 크기가 커지고, 여기에 softmax 함수가 적용되면 각 차원의 값이 매우 작은 경사도(gradient) 영역으로 이루어진 값을 갖게 한다. 이를 방지하기위해  로 나눈다.
로 나눈다.

<그림 18. Scaled Dot-Product Attention 구조>
결국 위 그림 18의 ③의 파란색 박스는 앞의 유튜브 검색에서 보았던 Query 와 Key 행렬 간에 유사도를 산출하는 식이다. 여기에 softmax layer 를 통과하면 아래 그림 19와 같이 0과 1사이의 값으로 변환된 Attention Filter 가 출력된다.

<그림 19. Softmax 함수 적용 후의 attention filter>
아래 그림 20을 보면, Scaled Dot-Product Attention 의 마지막 단계로 ①과 같이 Attention Filter 와 처음 그대로의 Original Value 행렬의 MatMul(행렬 곱)이 수행되어 최종적으로 Filtered Value 를 출력한다. 이는 위 그림 18의 ②의 Q, K, V 행렬 간의 attention 산출의 최종 출력이다. 다시 앞의 유튜브 검색에서의 Q, K, V 를 예로 들어 설명하면, Key1에 해당하는 동영상 컨텐츠Value1, 즉 문장 안에 주목해야할 단어만을 걸러낼 필터 값을 가진 것이다. 여기 까지가 Scaled Dot-Product Attention 이고 아직 하나가 더 있다.

<그림 20. 최종 filtered value 산출>
Multi-Head Attention
아래 그림 21의 ①과 같이 Scaled Dot-Product Attention 을 여러 개 덧붙임으로써(multi-head) 각각 다른 위치의 부분공간들의 묘사(representation)들을 연합하여 정보를 취득하게 하는 것이 단일 Scaled Dot-Product Attention 배치보다 유효하였다고 설명하고 있다. 이렇게 아래 ①을 여러 개 Concatenate(결합)하여 Linear 층을 통과시켜 Multi-Head Self-Attention 이 완성된다.

<그림 21. Multi-Head Attention>
결언
1편에 이어 Transformers 를 이해하는데 중요한 Linear layer, Query, Key, Value 개념 그리고 multi-head self-attention 동작에 대해 살펴보았다.