영화 추천 시스템
MovieLens 데이터세트가 제공하는 9700 여개의 영화와 수백만의 사용자의 평점이 담긴 데이터세트를 사용하여 영화 추천 시스템을 제작해보기로 한다. 추천시스템에 대한 일반적인 개념은 이전 뉴스레터10호에서 설명한 협업필터링과 행렬인수분해(Matrix Factorization) 부분을 참고하기 바란다. 본 추천시스템 개발은 NVIDIA A100 GPU X 1, Tensorflow 2.6, Keras 2.6, Python 3.8 환경에서 개발되었고 data_movies.xlsx 데이터는 약 3MB 의 크기다. 아래 그림1은 추천시스템 처리 절차에 대한 흐름도다.
<그림 1. 추천시스템 처리 절차>
상품 및 사용자 특성이 반영된 신경망 협업필터링 추천 시스템
본 시스템은 아래 그림2와 같이 전통적인 행렬인수분해(Matrix Factorization)를 통한 협업필터링에 더해서 최근의 신경망기반 협업필터링 논문에서 제시하는 신경망의 비선형성과 행렬인수분해의 결합을 통한 구성을 시도한다. 심층신경망의 완전연결층을 통한 정보를 부가적으로 넣어 줌으로써 행렬인수분해에서 혹시라도 빠뜨릴 수 있는 패턴과 특성들을 획득한다. 이러한 신경망 기반 협업필터링 시스템은 입력되는 데이터가 제공하는 가용한 모든 데이터를 아래 그림2와 같이 완전 연결층을 통하여 예측하는데 있어 모두 결합하여 반영할 수 있는 확장성을 제공한다. 협업필터링에 사용되는 사용자-상품 임베딩에 더해서 예를 들면, 영화 장르와 같은 상품 특성과 주중 시청 혹은 주말 시청과 같은 사용자 특성이 추가 정보로 신경망에 결합될 수 있다.
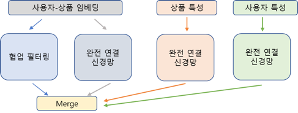
<그림 2. 신경망 기반 협업필터링 추천 시스템>
왜 심층신경망 기반인가?
일반적인 행렬 인수분해(matrix factorization) 접근방식은 그 선형성(linearity)으로 인해 모델의 표현력을 제한한다. 사용자와 상품(영화)이 동일한 잠재 공간에서 dot product의 선형 연산을 통해 평점을 산출한다. 이경우, 규정된 사용자끼리 만 연산이 수행되어 어떤 새로운 사용자와 나머지 모든 사용자 간의 관계가 묘사될 수 없다는 점이다. 심층신경망을 사용하는 이유는 보다 복잡한 관계를 잠재 공간(latent space)에서 허용하도록 심층신경망을 통하여 비선형(non-linear)함수를 학습하도록 하여 모델의 표현력을 향상시키는 것이다.
확률적 경사 하강법을 통한 행렬 분해
자 그럼, 우리가 살펴보려고 하는 문제를 생각해보자. Matrix factorization(MF, 행렬인수분해)는 추천 시스템에서 사용되는 협업 필터링(CF, Collaborative Filtering)중 대표적인 알고리즘이다. Matrix factorization 알고리즘은 아래 그림3과 같이 사용자-상품 간 상호작용 행렬을 두개의 저차원의 정사각형 행렬로 분해해 작동하게 표시된다. 우선 데이터로부터 ④와 같은 사용자-상품(영화)의 행렬을 만든다. 실제로는 ④의 노란색 셀과 같은 곳에만 값을 알 수 있고 나머지 값들을 모른다. 신경망을 통해 입력되면 ①의 사용자-특성 과 ②의 상품별-특성의 정사각형 행렬로 분해된다. 머신러닝이 ①과 ②에 임의의 행렬 초기 값을 가지고 시작한다고 가정해보자. 좌측의 Amy 사용자의 영화1 값이 ③과 같이 행렬 내적(dot product)를 통하여 1.44 라는 값을 가지게 된다. 머신러닝은 우측의 Amy 사용자의 영화1에 대한 평점 3과 방금 계산된 1.44를 비교하여 손실(loss)차가 있음을 파악하고 이 손실을 최소화되도록 확률적 경사 하강법(stochastic gradient descent)를 통한 훈련을 시행한다. 이를 통하여 F1과 F2, 즉 예를 들면, 로맨틱 과 액션이 영화 장르의 특성 값을 ①과 ②의 저 차원 행렬이 보유하게 된다. 따라서 만약 ④의 Bill 의 영화 3의 평점을 모른다면, ③과 같은 방식으로 행렬 내적 곱을 통하여 값을 예측할 수 있게 된다.

<그림 3. 행렬 인수분해 값을 찾기 위한 훈련>
데이터 로드 및 products feature engineering
우선 아래 그림4의 ①과 같이 data_movies.xlsx 에서 products sheet 만 로드 한다. ②와 같이 dtf_products 판다스 데이터프레임중에 ‘genres’가 없는 데이터를 제외한다. ③에서 ‘title’에 있는 특수문자를 제거한다.

<그림 4. products feature engineering>
④에서 ‘title’중 마지막 연도표시의 괄호를 벗기고 정수화 한다. ⑤에서 년도가 2000년 이상인 경우 1로 표시한다.
Users feature engineering
아래 그림 5의 ①과 같이 users sheet 만 로드 하되 10,000 record 만 로드 한다. ②에서 timestamp 형식을 바꾸고 ③에서 6에서 20시 사이를 1로 표시하는 daytime 컬럼 생성, ④는 date.weekday() 에서 정수로 요일을 반환. 즉 5,6 은 토,일요일로 weekend 에 1로 표시.

<그림 5. users feature engineering>
데이터 정제
아래 그림 6과 같이 사용할 컬럼만 정제한다. ①은 4개의 컬럼을 product를 인덱스로 하여 구성, ②의 users 데이터프레임은 3개 항목으로, “y”는 평점.
<그림 6. 데이터 정제>
이전 그림 5에서 추출한 daytime 과 weekend 변수를 나중에 신경망에 추가적으로 입력되는 맥락적(context) 정보로 사용하기위해 아래 그림 7과 같은 context dataframe을 생성한다.
< 그림 7. context dataframe 작성>
Products-Features matrix
Products 를 가지고 우선 products-features 행렬을 구성한다. 아래 그림8과 같이 genres로부터 장르 값들을 뽑아낸다. ①은 “genres”컬럼에서 “|”를 제거 후 tags로 담아, ②에서 columns에 대입하고 ③에서 장르가 없는 데이터를 제거. ④를 통하여 ‘genres’에 컬럼이 있는 위치에 해당되면 값 1을 표시하는 products 데이터프레임 생성.


<그림 8. products-features 행렬 구성>
Users-Products matrix
users 데이터프레임을 가지고 users-products 행렬을 구성한다. 아래 그림 9의 ①에서 피봇하기 전에 tmp에 복사. ②users df 를 “user”를 index로, 컬럼은 “product”고 값은 “y”인 평점인 매우 sparse 한 df_users 생성. ③을 통하여 missing_cols엔 평점이 없는 컬럼 인덱스가 담김. ④에서 해당 컬럼에 NaN을 삽입. ⑤에서 컬럼 sorting.

<그림 9. users-products 행렬 생성>
생성된 users-products 행렬을 아래 그림10과 같이 seaborn 라이브러리의 heatmap을 사용하여 표시해본다. ①에서 df_users.isnull() 로 null 값이 있는 곳이 true로 표시되고, vmin 과 vmax 는 colormap 의 단계를 0에서 1의 두 단계로, cbar=False 로 옆에 나타나는 color bar 는 숨기도록 했다. 무척 희박한(sparse)행렬이다.

지금까지 추천시스템 처리 절차 중에 데이터 로드 및 전 처리, products-features 행렬과 users-products 행렬을 생성하고 users-products 행렬의 feature 값들의 범위를 0.5~1.0 사이로 정규화 하였다. Users-products 행렬을 생성하고 가시화하는 것까지 살펴보았다. 2편에서는 전 처리, 협업필터 모델 설계, 심층망 기반 모델 설계 그리고 상품 및 사용자 특성을 입력으로 하여 모델을 훈련 및 테스트하고 평가하는 부분을 살펴보겠다.
댓글 없음:
댓글 쓰기