1편에 이어 2편에서는, 전 처리, 협업필터 모델 설계, 심층망 기반 모델 설계 그리고 상품 및 사용자 특성을 입력으로 하여 모델을 훈련 및 테스트하고 평가하는 부분을 살펴보겠다.
전 처리 (정규화 및 분할)
신경망에 입력하기위해 데이터를 아래 그림11과 같이 sklearn 의 MinMaxScaler 를 사용하여 df_users 의 feature 들 값의 범위를 0.5~1 사이의 값으로 정규화 한다.
<그림 11. df_users features 값 정규화>
아래 그림 12의 ①에서 users x products 로 구성된 df_users의 컬럼의 80%를 split으로 정하고 ②에서 split 만큼을 train에 ③에서 나머지를 test 로 할당. 전체 9,741 column 의 80% 인 7,792 컬럼을 보유한다.

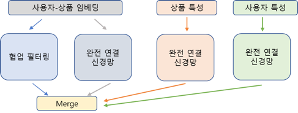
신경망 추천시스템에 결합되는 정보들
협업필터 모델 설계 목적은 user와 product 행렬의 생성이다. user-product쌍이 입력이고 출력은 평점이다. 우리가 활용하려고 하는 데이터를 한번 살펴보자.
목표 변수: 고객 평점이다. 직접 주어질 수도 있고 시청 시간 등으로 추정할 수도 있다.
상품 특성들(features): 우리의 경우는 영화의 장르다.
사용자 프로파일: 사용자에 대한 인구통계학적, 시청시간 같은 행위적 정보들이다.
맥락적 정보(context): 우리의 경우 평가와 관련된 주중 혹은 주말 여부 정보다.
1편의 그림2와 같이 우선 추가적으로 신경망에 결합될 상품 특성들(features)과 맥락적 정보(context)들을 아래 그림 13과 같이 생성한다. ①과 같이 genres 와 name을 제거하여 old 컬럼과 19개 장르를 포함한 상품 특성(features) 정보, ②에서 context중에 user와 product를 제거하여 사용자가 언제 평점을 주는 지에 대한 정보인 daytime 과 weekend 컬럼을 맥락 정보로 사용한다. context는 1편의 그림 7 참고.

< 그림 13. features 와 context 생성>
Train 과 Test에 feature 와 context 부가정보 추가
아래 그림14의 ①과 같이 판다스 데이터프레임의 stack() 함수를 사용하여 컬럼 별 내용을 인덱스별로 쌓는다. 그림12의 df_train 이 사용자별 영화의 sparse 한 행렬 구조였다면 stack()함수를 통해 영화 컬럼 별 내용을 사용자 인덱스별로 쌓는다. 영화 평점이 없는 것은 제외(dropna=True)하고 인덱스를 리셋하고 컬럼의 첫번째 이름인 평점을 “y”로 변경한다. ②에서 여기에 features들을 앞의 ①의 내용의 고유 값들을 왼쪽(how=’left’)에 두고, 추가할 features 데이터프레임을 왼쪽 ‘product’ 열을 기준으로(left_on=”product”) 추가할 때 오른쪽 데이터프레임의 인덱스를 join key 로 사용(right_index=True). 여기에 더해서 ③에 context 데이터프레임을 왼쪽에 이어서 추가.

아래 그림 15와 같이 test 데이터프레임도 ①과 같이 products 데이터프레임에서 genres와 name 을 제거한 features 데이터프레임을 위 train과 같이 병합한다.

<그림 15. test 에 features 와 context 추가>
상품 및 사용자 특성이 반영된 심층망 기반 모델 설계
심층망 기반 협업필터는 행렬 인수분해 와 신경망을 결합한다. 그리고 여기에 더해 심층망 기반의 장점인 확장성을 활용하여 feature 와 context 가 결합된 모델을 작성한다. 우선 신경망과 결합될 행렬 인수분해(matrix factorization)모델을 구축한다. 아래 그림16의 ①은 usr와 prd의 임베딩 출력차원 크기로 50을 정했다. ②users 데이터프레임의 행과 열을 usr, prd 로 할당 ③feature 와 ④context 입력 층 구성을 위해 크기가 필요 ⑤users 입력 층은 1자리 입력 ⑥users 임베딩은 (None, 1, 50)의 출력 모양을 갖는다. None 은 batch 크기. ⑦mf_users 와 mf_products 를 dot product 실행하기위해 출력 모양을 각각 (None, 50)으로 reshape한다. ⑧mf_users 와 mf_products 를 ⑧은 mf_users와 mf_products 를 행 중심(axes=1)으로 dot product.

<그림 16. 행렬 인수분해 구축>
이어서 아래 그림 17은 다중 퍼셉트론 신경망(multi layer perceptron)기반 구축이다. ①은 mlp_users와 mlp_products를 Keras의 layers.ConcaTenate로 결합(concateneate). ②는 Dense층을 units=25, relu 활성화함수로 생성.

<그림 17. 신경망 기반 구축>
다음으로 상품 및 사용자 특성을 추가한 층을 생성하고 이 모든 4가지 모델을 결합한 모델을 작성하고 컴파일한다. ①은 feat차원의 입력을 받는 입력층 ②는 feat만큼의 unit을 보유하는 Dense 층으로 relu 활성화함수를 통과시킨다. 아래 contents도 마찬가지. ③은 지금까지 생성한 4가지 협업필터, 다중퍼셉트론, feature 및 context를 결합(concat)한다. ④결합된 4개 입력을 unit 하나의 dense 층에 linear 활성화함수를 통과시킨다. Keras의 activation.linear는 입력 값이 변화되지 않고 그대로 출력된다.
 <그림 18. 상품, 사용자 특성 부가 및 모델 컴파일>
<그림 18. 상품, 사용자 특성 부가 및 모델 컴파일> 아래 그림 19의 ①과 같이 입력으로 train의 user, product, feature, context를 정의하고 출력으로 평점 y 를 설정하여 ②에서 100회, epoch batch 크기는 128, train의 30%를 validation으로 설정하여 model.fit 을 통해 훈련을 시행한다. 100회 훈련 후 validated loss 가 0.1890으로 표시된다.

훈련된 모델에 4가지 입력을 넣어 아래 그림 20의 ①과 같이 모델이 사용자의 영화에 대한 평점을 예측한 값 “yhat”을 구한다.

아래 그림 21은 특정사용자를 지정하고, 해당 사용자의 test 의 영화 top 5와 모델이 예측하는 영화 top 5를 비교하여 평가하는 부분이다. 우선 처음 사용자로 (user=1) 정하고 ①에서 사용자1이 관람한 영화의 평점 “y” 값의 내림차순으로 test 데이터세트의 영화(product)를 상위 5개를 표시한다. ②에서 마찬가지로 사용자1에 대한 모델이 예측한 평점 “yhat” 값의 내림차순으로 영화(product) 상위 5개를 출력. ③은 평점순서대로 대응되는 test 데이터세트의 영화(상품)번호, ④는 모델이 예측한 영화(상품)번호. ⑤true positive는 5개중에 4개를 맞추어 80%. ⑥과 ⑦ accuracy와 mrr은 순서가 중요하여 점수가 낮다.

mrr 평가지표는 아래 그림 22와 같이 제안된 결과의 순위에서 상호간(reciprocal)의 순서 위치의 평균을 산출한다. 아래 예에서는 (1/3 + 1/2 + 1)/3 = 11/18 이다. 1에 가까울수록 좋은 점수이다.

결언
지금까지 추천시스템에서 협업필터 방식의 모델이 비선형 함수를 학습하도록 하여 모델의 표현력을 향상시키도록 협업필터, 심층신경망, 상품 및 사용자특성을 모두 결합하여 반영하는 신경망기반 추천시스템의 작동 방법을 살펴보았다.